AI image generators have come a long way since their inception, greatly influencing the way we perceive and interact with digital visuals.
Debuting in January 2021, DALL-E was a pioneer, pushing the boundaries of what we thought possible with AI in art. It had the unique ability to generate images from simple text descriptions, so called “prompts”, such as "a chair in the shape of an avocado."
 |  |  |  |
The most remarkable feature of DALL-E was its ability to create never-before-seen objects, a testament to its profound learning capacity and the scope of AI's creative potential. It showcased that an AI could, in fact, dream up surreal, abstract concepts and bring them to life, and it was the first time AI had demonstrated to a general audience such a level of accurate representation.
Diffusion models are a family of probabilistic generative models that progressively destruct data by injecting noise, then learn to reverse this process for sample generation.

Source: Diffusion Models: A Comprehensive Survey of Methods and Applications, Yang et al.
While DALL-E demonstrated impressive image generation from textual descriptions, it lacked nuanced control and resulted in occasional bizarre outputs. In contrast, Midjourney capitalized on these shortcomings, reducing unaesthetic results, and better understanding user intent. Emerged in February 2022, Midjourney harnessed the power of generative AI and used it to help users create images with a specific aesthetic style. This enabled the creation of visuals for practical uses, including web design and advertising.
 |  |  |  |
Introduction of Stable Diffusion in August 2022, has marked another major milestone in AI image generation. As an open-source project, Stable Diffusion opened the gates for a myriad of creators, researchers, and developers to adapt and enhance the technology. This democratic access laid the foundation for new tools like Automatic1111 and InvokeAI, making advanced technology freely accessible to all.
Stable Diffusion is a large text-to-image diffusion model trained on 170M images from laion-5B and 595,000 steps laion-aesthetics v2.5+.
The model is essentially an U-net with an encoder, a middle block, and a skip-connected decoder. Both the encoder and decoder have 12 blocks, and the full model has 25 blocks (including the middle block). In those blocks, 8 blocks are down-sampling or up-sampling convolution layers, 17 blocks are main blocks that each contains four resnet layers and two Vision Transformers (ViTs). Each Vit contains several cross-attention and/or self-attention mechanisms. The texts are encoded by OpenAI CLIP, and diffusion time steps are encoded by positional encoding.
Stable Diffusion uses a pre-processing method similar to VQ-GAN to convert the entire dataset of 512 × 512 images into smaller 64 × 64 “latent images” for stabilized training.

Source: High-Resolution Image Synthesis with Latent Diffusion Models, Rombach et al. & Adding Conditional Control to Text-to-Image Diffusion Models, Zhang and Agrawala
Dreambooth and Textual Inversion, signified another leap forward. While foundational models were powerful tools in their own right, they lacked the capacity for personalization and the ability to mimic the appearance of subjects in diverse contexts.
Dreambooth addressed this limitation by introducing a new approach for the "personalization" of text-to-image diffusion models. With only a handful of images as input, Dreambooth could fine-tune a pretrained text-to-image model to create a unique identifier for a specific subject. This enabled subject recontextualization and view synthesis.
Finetune a text-to-image diffusion model with the input images paired with a text prompt containing a unique identifier and the name of the class the subject belongs to, in parallel, class-specific is applied prior preservation loss, which leverages the semantic prior that the model has on the class and encourages it to generate diverse instances belong to the subject’s class using the class name in a text prompt (e.g., “A dog”).
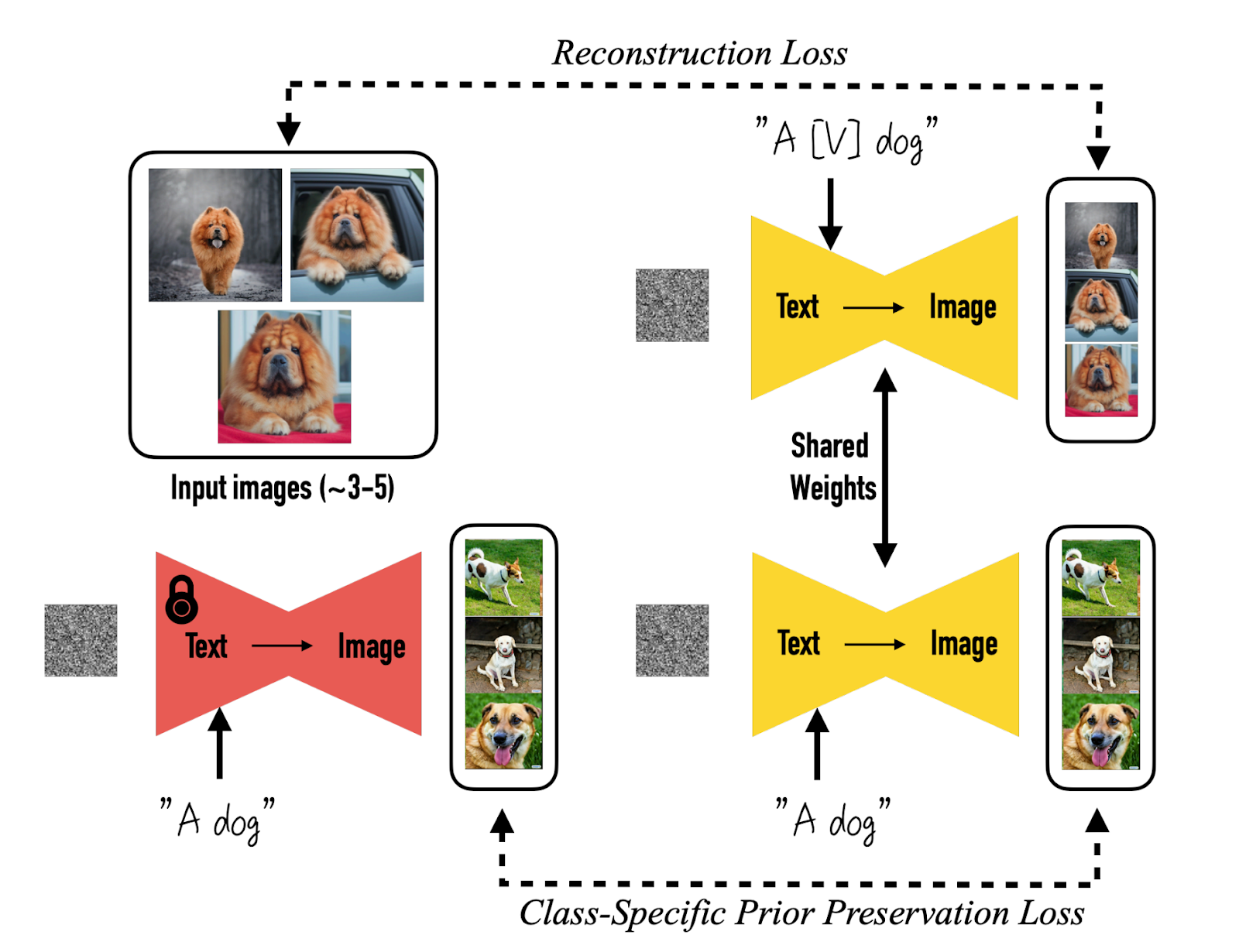
Source: DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation, Ruiz et al.
One major challenge in generating images with AI is accurately translating text instructions into the desired output image. Due to the contextual nature of instructions, AI models may interpret them differently from what the user intended. A significant development in this field is the utilization of other images to provide color-level details and guide AI models, often in conjunction with text prompts. This approach is commonly referred to as "Image-to-Image".
A more advanced technique in image-to-image generation is ControlNet, which emerged in February 2023. ControlNet allows for the precise control of a diffusion model by incorporating task-specific conditions. This enables the use of conditional inputs such as edge maps, segmentation maps, and keypoints, thereby enhancing the control and manipulation capabilities of large diffusion models.
ControlNet manipulates the input conditions of neural network blocks so as to further control the overall behavior of an entire neural network.
ControlNet is used to control each level of the U-net of Stable Diffusion. Connection to ControlNet is computationally efficient: since the original weights are locked, no gradient computation on the original encoder is needed for training.
Example of Controlling Stable Diffusion with Openpifpaf pose:

Source: Adding Conditional Control to Text-to-Image Diffusion Models, Zhang and Agrawala
Groundbreaking achievements of these developments have paved the way for services that specialize in training AI to generate images from face photos. Now, even novice users can take advantage of user-friendly platforms that utilize Stable Diffusion and Dreambooth.
 |  |  |  |
This exciting development opens up a world of possibilities, from creating personalized avatars to conducting virtual photo sessions for platforms like LinkedIn, Instagram, or Tinder. Additionally, these services enable the production of captivating visuals for advertising campaigns and websites. The creative industry is undergoing a transformative shift with accessible AI image generation.
In Part 2, we will delve into an overview of AI image generators.